The increasing demand for natural language processing (NLP) applications has led to a surge in the development of Large Language Models (LLMs). However, as these models grow in size and complexity, their computational requirements also increase, making them slower and more power-hungry. Groq's LPU (Language Processing Unit) Inference Engine addresses this challenge by providing a dedicated processing system that can handle computationally intensive applications like LLMs with ease.
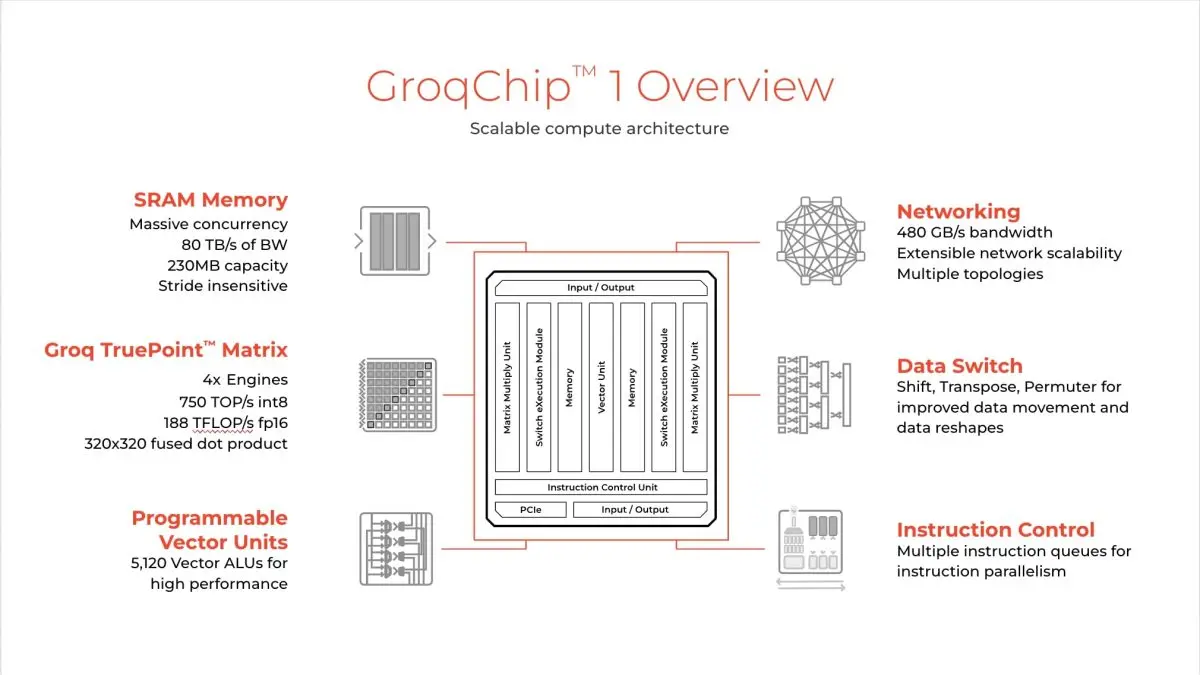
Traditionally, LLMs have relied on Graphics Processing Units (GPUs) for acceleration. While GPUs are designed to handle parallel computations efficiently, they often struggle with sequential components, which are inherent in many NLP tasks. The LPU Inference Engine was specifically designed to address this limitation by focusing on exceptional sequential performance and instant memory access.
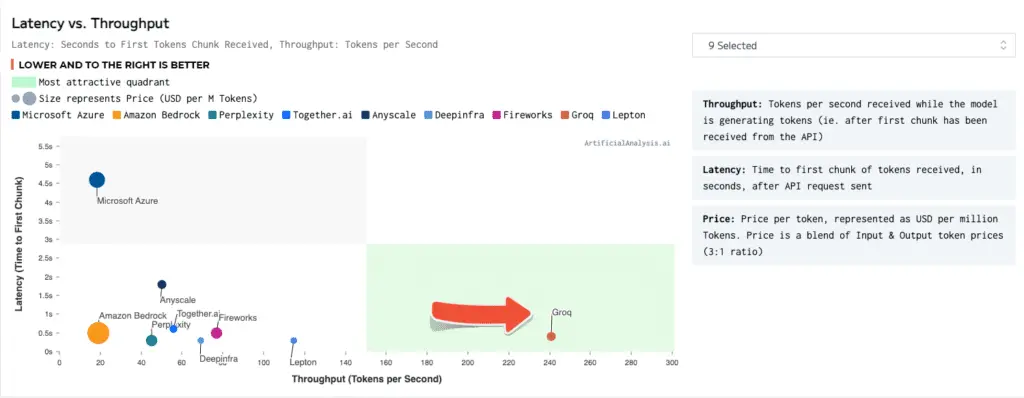
Groq's LPU systems have set industry benchmarks by achieving over 300 tokens per second per user on the Llama 2 70B model. This level of performance is unprecedented and marks a significant breakthrough in LLM acceleration.
You can read more about Groq here.
The Groq LPU Inference Engine has revolutionized the speed at which Large Language Models can be processed, making it an ideal fit for various NLP applications. Its exceptional sequential performance and instant memory access have set industry benchmarks, making it a crucial tool in the field of artificial intelligence.
By providing a dedicated processing system that can handle computationally intensive applications like LLMs with ease, Groq's LPU has opened up new possibilities for AI development. The implications of this technology are vast and varied, from improved language understanding to more efficient data analysis.
As AI continues to evolve and become an increasingly integral part of our lives, the need for faster and more efficient processing systems like the Groq LPU will only continue to grow. The future of machine learning has never looked brighter.